구현(자바)
참조문헌1
참조문헌2
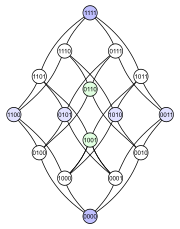
Min-max heap은 min heap과 max heap의 장점을 취해 구현한 완전이진트리이다.
홀수번째 깊이의 노드들은 min heap을, 짝수번째 깊이의 노드들은 max heap을 구성한다.
기존 min heap, max heap과 같이
- 삽입, 삭제에 대해 로그 시간복잡도
- 초기 구축에 선형 시간복잡도
을 가지면서도 min, max값에 대해 모두 상수 참조시간을 갖는 매력적인 자료구조이다.
구현에는
- 원소를 트리 위에서 아래로 내리는 TrickleDown (heapify 및 삭제에 쓰인다)
- 원소를 트리 아래에서 위로 올리는 BubbleUp (삽입에 쓰인다)
함수가 필요하다.
heapify 연산의 경우 첫번째 인덱스를 1로 갖는 배열로 구현한 트리의 경우
기존 힙과 같이 인덱스 size(tree) / 2 부터 1까지(자식을 갖는 노드들을 아래에서 위로 거슬러 올라감, n번째 깊이의 노드들은 n-1번째 깊이의 노드들보다 먼저 연산되어야 한다) 거꾸로 TrickleDown 연산을 수행해주면 된다.
TrickleDown 연산을 보자
procedure TrickleDown(i)
i는 array내의 위치를 뜻함
if i는 min level then
TrickleDownMin(i)
else
TrickleDownMax(i)
endif
procedure TrickleDownMin(i)
if A[i]가 children을 가지고있음 then
m := A[i]의 children 및 grandchildren 중
(존재하는 경우에) 가장 작은 요소의 인덱스
if A[m]이 A[i]의 grandchild임 then
if A[m] < A[i] then
swap(A[m], A[i])
if (A[m] > A[m의 부모]) then
swap(A[m], A[m의 부모])
endif
TrickleDownMin(m)
endif
else A[m]이 A[i]의 child임
if A[m] < A[i] then
swap(A[i], A[m])
endif
endif
TrickleDownMax의 경우 TrickleDownMin에서 부등호의 방향만 다르게 구현해주면 된다.
해당 자료구조가 갖는 성질에 비해 구현이 매우 쉽고 간단하다.
기본적으로 A[i]의 grandchild, child를 살펴 가장 작은값(A[m])을 살펴 swap할지를 결정하는데,
A[i]가 그 어느값보다 작을 경우:
이미 해당 min level의 성질을 만족함, 더이상 연산을 수행할 필요 없음.
A[m]이 child일 경우:
A[i]와 A[m]의 위치만 swap 후 종료, 삭제의 경우 이미 트리는 min-max heap의 성질을 만족하는 상태이며,
heapify중일 경우에는 heapify 연산이 아래 레벨부터 위의 레벨 순서로 TrickleDown을 수행하기 때문에 swap된 기존 A[m]값은 자연히 올라갈것임.
A[m]이 grandchild일 경우:
A[i]와 A[m]의 위치를 바꾸고, 또 A[m]의 부모와 비교하여 값이 A[m]이 더 클경우 A[m]과 A[m의 부모]를 swap한다.
이는 기존의 A[i]값이 max heap level에 속해야 할 값이었을 경우 leaf노드 끝까지 내려갔다가 다시 올라오는 연산을 할 수고를 덜게해준다.
기존 A[i]값이 더 상위의 max heap level에 속해야 할 값이라면, heapify 연산중에는 상기한 바와 같이 자연히 올라가게 될 것이다.
삭제의 경우에는 이미 트리는 min-max heap의 성질을 만족하는 상태이기에, 이전 i의 grandparent의 TrickleDownMin 연산에서 max heap level에 속했어야 옳다
마지막으로 grandchild와 swap에 성공했을 경우엔 TrickleDownMin을 또 다시 호출하여 min-max heap의 성질을 만족할 때까지 내려가도록 한다.
procedure Deletion(i)
A[i] := A[length]
length := length - 1
TrickleDown(i)
procedure Insertion(K)
A[length] := K
BubbleUp(length)
length := length + 1
마지막으로 insertion에 쓰이는 BubbleUp의 경우 TrickleDown보다도 더 간단하다.
procedure BubbleUp(i)
i는 array내의 위치를 뜻함
if i는 min level then
if i의 부모 존재 then
if A[i] > A[i의 부모] then
swap(A[i], A[i의 부모])
BubbleUpMax(i의 부모)
else
BubbleUpMin(i)
endif
endif
else
if i의 부모 존재 then
if A[i] < A[i의 부모] then
swap(A[i], A[i의 부모])
BubbleUpMin(i의 부모)
else
BubbleUpMax(i)
endif
endif
endif
procedure BubbleMinUp(i)
if A[i]가 grandparent를 가짐 then
if A[i] < A[i의 grandparent] then
swap(A[i], A[i의 grandparent])
BubbleUpMin(i의 grandparent)
endif
endif
역시 BubbleMaxUp의 경우 부등호의 방향만 다르게 해주면 된다.
먼저 A[i]자신의 min, max level 여부를 살피고 반대되는 성질의 level(A[i]의 parent가 위치한 level)에 진입할 수 있는지를 확인한다
A[i]가 min level이고 A[i]의 parent보다 클 경우 : max heap level로 진입
A[i]가 min level이고 그 외 : min heap level로 진입
A[i]가 max level이고 A[i]의 parent보다 작을 경우 : min heap level로 진입
A[i]가 max level이고 그 외 : max heap level로 진입
그리고 BubbleMinUp, BubbleMaxUp 각각에서는 min-max heap의 성질을 만족할 때까지 계속 grandparent와 비교하며 요소를 위로 swap해주면 된다.
이렇게 구현된 min-max heap의 경우 root노드는 min값을, 그리고 root의 자식노드 둘 중 하나가 max값을 가지게 된다.